News
Research Firm on AWS Outage: 'Don't Let Headlines Drive Strategy'
Following the recent AWS outage that disrupted a wide spectrum of services, Gartner analyst Lydia Leong urged organizations to stay calm and focus on resilience rather than abandoning the cloud altogether.
In a post titled "Don't Let the AWS Outage Erode Your Trust in the Cloud," published Oct. 20, 2025, she described the event as "a wake-up call, but not a reason to abandon ship."
The AWS outage on Oct. 20, 2025, originated in the US-East-1 region in Northern Virginia, where a DNS resolution problem affected key backend services such as DynamoDB and spread to dependent systems across the cloud platform.
The disruption began around 3 a.m. ET and caused elevated error rates and latency across a wide range of applications. Many internet-facing services that rely on AWS--including consumer apps, enterprise platforms, and parts of AWS's own management tools--experienced degraded performance or downtime for several hours. Full recovery was achieved later the same day, although some workloads required additional time to clear operational backlogs. The incident demonstrated how a single-region fault can have global cascading effects and highlighted the importance of resilient architecture and dependency management in large-scale cloud environments.
But Leong noted it followed a "familiar pattern" seen across all hyperscale providers: "a regional event lasting less than a day, driven by a network dependency, but not affecting running compute instances themselves."
Her viewpoint was echoed in a social media post from the research firm:
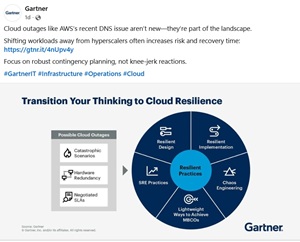 [Click on image for larger view.] 'DNS Issues Aren't New' (source: Gartner).
[Click on image for larger view.] 'DNS Issues Aren't New' (source: Gartner).
"Don't let headlines drive strategy. Let data do the talking," is a subhead in Leong's post, with accompanying commentary including: "Cloud outages make headlines because they affect so many people at once, but context matters. Every major provider has experienced similar events, from Microsoft Azure to Google Cloud Platform. The real differentiator is how well your organization plans for and recovers from inevitable disruption."
Leong advised against reactionary moves like repatriating workloads to on-premises infrastructure or switching to smaller sovereign clouds. Such shifts, she wrote, "often introduce new risks and may even slow down your recovery when things do go wrong." Instead, she encouraged IT leaders to strengthen architectural discipline through distributed design, updated runbooks, and routine failover testing. "No cloud provider can promise zero downtime," she said, emphasizing that what matters is "how they prepare and respond."
Leong credited AWS for improving transparency and fault isolation since its 2021 outage. The recent disruption was "completely confined to US-East-1," she observed, which "shows progress in fault isolation" and gives CIOs actionable data for risk management rather than guesswork.
The analyst also warned that multicloud deployments, often touted as a resilience strategy, can backfire. "Pursuing multicloud resilience can cost more than it saves," Leong wrote, adding that the better path for most organizations is to "maximize single-cloud resilience first."
Leong concluded that public cloud remains the most reliable and scalable infrastructure model if organizations invest in resilience from the start. "Don't let fear steer you toward costly or ineffective alternatives," she wrote. "Double down on architecture, process discipline and transparent partnerships with your providers."
About the Author
David Ramel is an editor and writer at Converge 360.