News
AWS Details How to Pick Right AI Model with 360-Eval Framework
AWS has outlined a systematic way to choose the right large language model (LLM) for a given task, emphasizing measurable evaluation over subjective impressions.
The guidance appears in the AWS Machine Learning Blog post titled "Beyond vibes: How to properly select the right LLM for the right task."
The post, authored by AWS's Claudio Mazzoni and Anubhav Sharma and published Oct. 17, 2025, promotes a structured approach that moves beyond ad-hoc, vibes-based testing toward comprehensive, empirically driven evaluations. It presents an open-source, lightweight, code-first framework, 360-Eval, to orchestrate multi-model, multi-metric comparisons, including options for models hosted in Amazon Bedrock or Amazon SageMaker, as well as external APIs.
The project's GitHub repo describes the framework:
This framework implements a "LLM-as-a-Jury" methodology based on research from Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models, each evaluation is composed of an ascending ranking score of 1-5 and, where the total LLMs evaluate responses are tallied and their mean calculated, this becomes the final score (if an average of the evaluation fails to achieve a score of 3+ across any evaluation dimension is deemed to have failed, value can be changed). This technique provides more reliable and balanced evaluations compared to single-judge, PASS | FAIL methods.
"A more holistic approach entails evaluating the model based on metrics around qualitative and quantitative aspects, such as quality of response, cost, and performance," the post said. "This also requires the evaluation system to compare models based on these predefined metrics and give a comprehensive output comparing models across all these areas. However, these evaluations don't scale effectively enough to help organizations take full advantage of the model choices available."
The authors argue that informal one-off trials can miss subtle errors and unsafe behavior, and provide no criteria for improvement. They write that "no single metric can capture what makes an LLM response 'good'," and recommend evaluating across multiple dimensions aligned to product requirements.
Core decision dimensions highlighted in the post include:
- Accuracy
- Latency
- Cost-efficiency
To operationalize subjective criteria, the post notes that teams can use human or LLM-as-a-judge scoring to "move from 'I like this answer more' to 'Model A scored 4/5 on correctness and 5/5 on completeness.'”
Quality Criteria for LLM Outputs
In addition to the decision dimensions above, the post outlines evaluation criteria for judging response quality. These criteria focus on how well a model answers and presents information for a given prompt:
- Correctness (accuracy)
- Completeness
- Relevance
- Coherence
- Following instructions
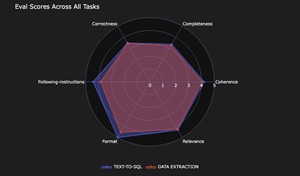 [Click on image for larger view.] Eval Scores Across All Tasks (source: AWS).
[Click on image for larger view.] Eval Scores Across All Tasks (source: AWS).
The authors suggest scoring these criteria with structured rubrics or automated judges, and, where possible, using ground-truth datasets for objective checks.
The guidance describes a code-first workflow that defines a dataset of prompts and expected outputs, selects candidate models, and captures inference metadata such as time-to-first-token, total tokens, and pricing. The framework then applies the chosen judge metrics and produces an HTML report with an executive summary, latency and cost breakdowns, and task-level analysis.
An example scenario evaluates multiple models on two tasks: extracting entities and attributes from requirements text, and generating PostgreSQL create table statements. The report visualizations show differing tradeoffs: one model is fastest, another is cheapest, and a third ranks highest on correctness and completeness. The example concludes that organizations may choose different models by tier, prioritizing accuracy for premium use cases and price-performance for basic tiers.
"As FMs become more reliant, they can also become more complex," the authors said in conclusion. "Because their strengths and weaknesses more difficult to detect, evaluating them requires a systematic approach. By using a data-driven, multi-metric evaluation, technical leaders can make informed decisions rooted in the model's actual performance, including factual accuracy, user experience, compliance, and cost."
About the Author
David Ramel is an editor and writer at Converge 360.