AWS Step-by-Step
Moving Large Volumes of Data to Amazon S3 with Snowball
It has been said that one of the most compelling reasons to use the public cloud is that public cloud providers are well-suited to running really large-scale workloads.
That's all well and good, but what do you do if you have a really big workload running in your datacenter and you want to move it to the Amazon Web Services (AWS) cloud? It isn't exactly practical to transfer petabytes of data across an Internet connection.
If you need to move large amounts of data to AWS, then you don't necessarily have to transfer that data across the Internet. AWS offers a service called Snowball, which it first unveiled at the 2015 AWS re:Invent conference, that exists solely to help AWS subscribers with large-scale data migrations. As AWSInsider reported when Snowball debuted:
[Snowball] gives organizations a literal briefcase to physically transfer large amounts of data to AWS, a process that could take days or months if done over the air. Snowball appliances are ruggedized storage containers that organizations can order through their AWS Management Console. The appliances, which start at 50TB, feature "tamper-proof" closures, impact-resistant materials, built-in cabling, and digital shipping labels to reduce the likelihood of shipping mistakes.
The first thing that you need to know about Snowball is that it isn't suitable for every situation. If you need to transfer several terabytes of data, then you may be better off uploading that data in the usual way because of the costs involved in using Snowball. Snowball should be reserved for data transfer jobs that are just too big to do in any other way.
To use Snowball, you will need to log into the AWS Management Console, choose the Snowball option from the home screen, and click Get Started. This will cause AWS to launch a wizard that walks you through the process of planning a Snowball job. As you can see in Figure 1, a Snowball job can be used to move data to Amazon Simple Storage Service (S3) or, since a feature update in March this year, to export data from S3.
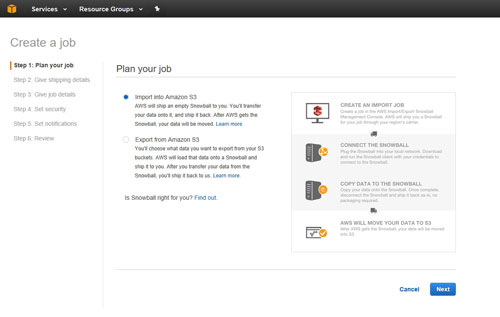 [Click on image for larger view.] Figure 1: You can use Snowball to move data to or from Amazon S3.
[Click on image for larger view.] Figure 1: You can use Snowball to move data to or from Amazon S3.
In the case of an import operation, you will need to create an import job. This process consists of providing your shipping information and some details about the data that is to be transferred. Upon doing so, AWS will ship you a physical appliance that you can connect to your network. In most cases, organizations choose to transfer data to the Snowball appliance by using the Snowball client. It is possible, however, to transfer data programmatically. Once the transfer is complete, you can ship the appliance back to AWS and its contents will be transferred to S3.
Now that I have explained the basics of using Snowball, there are a few important things that you need to know. First, like any physical appliance, Snowball does have a capacity limit. In the United States, Snowball appliances come in two different sizes -- 50TB and 80TB. In other regions, Snowball appliances can accommodate 80TB of data.
In spite of the Snowball appliance's capacity limit, it is possible to transfer really big data sets. The transfer operation must be divided into a series of jobs, with each job corresponding to one Snowball appliance. Thus, transferring large datasets involves the use of multiple appliances. Keep in mind, however, that AWS' default service limit only allows an organization to possess one Snowball appliance at a time. It you need to use multiple appliance simulations, then you will need to contact AWS to make arrangements.
Perhaps the most significant obstacle to using Snowball is the requirement that data remain static during transfer operations. If the data is modified during the copy process, then the data is invalidated and cannot be copied to S3. This is obviously a significant issue because any data set that is large enough to warrant using Snowball is probably being actively used.
As such, organizations will either have to plan to take the workload offline for a period of time, or come up with a way to ensure that the data will not be modified during the transfer. For example, an organization might create a storage snapshot prior to copying data to Snowball.
This brings up another important point: Transferring data to Snowball requires the use of a workstation. AWS recommends that you use the data's local host as a workstation (for the purposes of the file transfer). The reason for this is that the network can become a serious bottleneck. It is possible to transfer data to Snowball over a network link, but large frames are not supported, which can further diminish performance.
Regardless of which computer you choose to use as a workstation, the workstation needs to have plenty of memory, processing power and throughput if it is to transfer the data efficiently.
As you can see, there are a number of logistical considerations that should be taken into account before you create a Snowball job. You will want to be sure to work out the details ahead of time, because there is a time limit of 90 days. AWS provides a number Snowball best practices here.
About the Author
Brien Posey is a 22-time Microsoft MVP with decades of IT experience. As a freelance writer, Posey has written thousands of articles and contributed to several dozen books on a wide variety of IT topics. Prior to going freelance, Posey was a CIO for a national chain of hospitals and health care facilities. He has also served as a network administrator for some of the country's largest insurance companies and for the Department of Defense at Fort Knox. In addition to his continued work in IT, Posey has spent the last several years actively training as a commercial scientist-astronaut candidate in preparation to fly on a mission to study polar mesospheric clouds from space. You can follow his spaceflight training on his Web site.