AWS Step-by-Step
Creating Alarms for Auto-Scaled AWS Workloads
It's easy enough to create an auto-scaling group in AWS, but how exactly does AWS know when a workload needs to be scaled? As Brien demonstrates, the entire process is based on alarms.
In my last column, I talked about how you can create an auto-scaling group for the purpose of automatically scaling workloads up or down in response to demand spikes.
Although setting up automatic scaling is a relatively easy thing to do, the entire process is based on the use of alerts. Alerts are the mechanism that tells Amazon Web Services (AWS) when a workload needs to be scaled. Since I didn't really get a chance to discuss alerts in the previous column, I wanted to take the opportunity to explain how to create an alert for use with an auto-scaling group.
The AWS console allows you to use a preexisting alarm, but you also have the option of creating an alarm as a part of the auto-scaling group creation process. If you look at Figure 1, for instance, you can see that there are a couple of existing alarms, but there is also an Add New Alarm link that you can click to create a custom alarm.
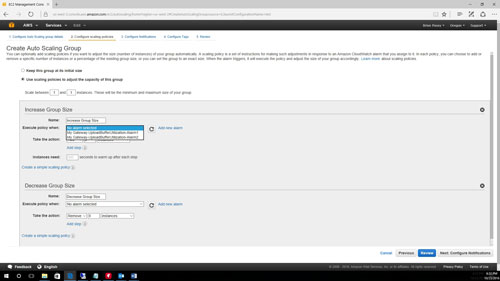 [Click on image for larger view.] Figure 1: You can use existing alarms, or you can click Add New Alarm to create a new alarm.
[Click on image for larger view.] Figure 1: You can use existing alarms, or you can click Add New Alarm to create a new alarm.
If you choose the option to add a new alarm, you will be taken to the dialog box that is shown in Figure 2. As you can see, this dialog box provides you with the option of sending a notification when a predefined threshold value is reached.
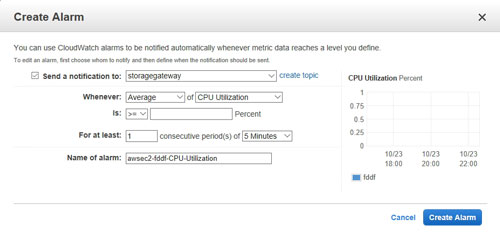 [Click on image for larger view.] Figure 2: These are the options for creating a new alarm.
[Click on image for larger view.] Figure 2: These are the options for creating a new alarm.
One important thing to keep in mind as you look at the figure above is that auto-scaling groups are tied to an instance. The Elastic Compute Cloud (EC2) console allows for the creation of instance-specific alarms. In other words, you could conceivably create an instance, create one or more alarms for the instance, and then build an auto-scaling group for the instance. If you were to do that, then you could use the instance's existing alarms as the basis for increasing or decreasing the group size, or you could create new alarms solely for the purpose of changing the group size.
Either of these approaches will work, but I recommend using the Create Alarm dialog box that is shown in Figure 2 any time you are going to use an alarm as a group-scaling mechanism. To show you why I make this recommendation, take a look at Figure 3 below. This figure shows the interface used to create an instance-specific alarm.
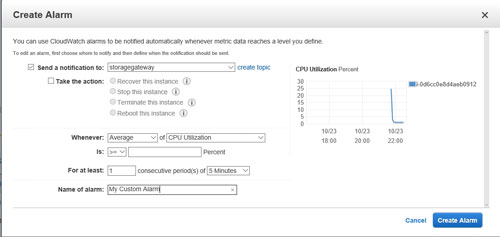 [Click on image for larger view.] Figure 3: This is what it looks like when you create an alarm for an instance.
[Click on image for larger view.] Figure 3: This is what it looks like when you create an alarm for an instance.
If you compare Figures 2 and 3, you will notice that when you create an alarm for an instance, you are given the option to take action. The available actions include Recover This Instance, Stop This Instance, Terminate This Instance and Reboot This Instance. If your goal is to scale the instance, then these actions really aren't appropriate. That's why these actions are not included on the dialog box that is shown when you create a new alarm through the auto scaler. Remember, the auto scaler is performing an action, but that action is the scaling of a workload.
The actions listed in Figure 3 would interfere with the scaling process if they were used. As such, you should not build any actions into an alarm that is to be used for auto-scaling purposes, with the exception of sending a notification. You probably won't always need to send a notification, but you do have that option.
As previously explained, it is the auto-scaling alarm's job to determine whether or not the workload needs to be scaled. It is ultimately up to the administrator to determine what criteria warrants scaling the workload. As you can see in Figure 4 below, the Create Alarm dialog box allows you to create alarms that are based on CPU utilization, storage I/O and network traffic. Once you determine what metric you want the alarm to monitor, you can set a threshold value for that alarm. For example, you might create an alarm that triggers an increase in group size when the average CPU utilization exceeds 90 percent.
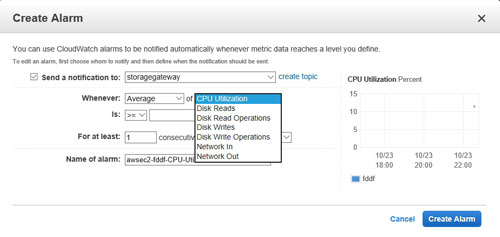 [Click on image for larger view.] Figure 4: You can base the alarm on a number of different metrics.
[Click on image for larger view.] Figure 4: You can base the alarm on a number of different metrics.
One more thing to pay attention to is the For at Least field shown in Figure 2. Notice in the figure that the default value is For at least 1 consecutive period of five minutes. The default values work well in many cases, but you can adjust this value if necessary. It is important, however, to set a reasonable threshold in order to prevent hair-trigger scaling.
To illustrate the point, consider an alarm that monitors CPU utilization. It is completely normal for an instance's CPU utilization to spike to 100 percent, but you wouldn't want a workload to scale in response to a brief activity spike. Scaling is better suited to sustained conditions, such as a heavy load that lasts several minutes.
As you can see, AWS makes it relatively easy to create alarms for use with auto-scaling groups. These alarms should be created in a way that detects conditions that warrant workload scaling, without being overly aggressive.
About the Author
Brien Posey is a 22-time Microsoft MVP with decades of IT experience. As a freelance writer, Posey has written thousands of articles and contributed to several dozen books on a wide variety of IT topics. Prior to going freelance, Posey was a CIO for a national chain of hospitals and health care facilities. He has also served as a network administrator for some of the country's largest insurance companies and for the Department of Defense at Fort Knox. In addition to his continued work in IT, Posey has spent the last several years actively training as a commercial scientist-astronaut candidate in preparation to fly on a mission to study polar mesospheric clouds from space. You can follow his spaceflight training on his Web site.