News
Microsoft Targets AWS Redshift with New Azure SQL Data Warehouse
Microsoft made no bones about who it was targeting with its new Azure SQL Data Warehouse during yesterday's opening keynote address at its Build developer conference.
"There are other data warehouse offerings in the market today," said exec Scott Guthrie, noting that Amazon Web Services Inc. (AWS) "has seen good uplift with its Redshift offering." Guthrie then said, "I want to spend a little time now talking about how Azure is even better" and put up a slide showing the advantages.
 [Click on image for larger view.]
Azure SQL Data Warehouse vs. AWS Redshift (source: Microsoft)
[Click on image for larger view.]
Azure SQL Data Warehouse vs. AWS Redshift (source: Microsoft)
Azure SQL Data Warehouse, which will be available as a preview in June, was designed to provide petabyte-scale data warehousing as a service that can elastically scale to suit business needs. In comparison, the AWS Redshift -- unveiled more than two years ago -- is described as "a fast, fully managed, petabyte-scale data warehouse solution that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence tools."
Guthrie yesterday pointed out what he said are numerous advantages that Azure SQL Data Warehouse provides over AWS Redshift, such as the ability to independently adjust compute and storage, as opposed to Redshift's fixed compute/storage ratio. Concerning elasticity, Microsoft describes its new service as "the industry’s first enterprise-class cloud data warehouse as a service that can grow, shrink and pause in seconds," while it could take hours or days to resize a Redshift service. Azure SQL Data Warehouse also comes with a hybrid configuration option for hosting in the Azure cloud or on-premises -- as opposed to cloud-only for Redshift -- and offers pause/resume functionality and compatibility with true SQL queries, Guthrie said. Redshift has no support for indexes, SQL UDFs, stored procedures or constraints, he said.
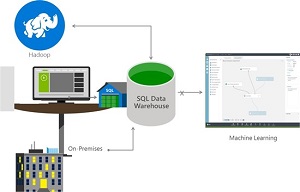 [Click on image for larger view.]
Introducing SQL Data Warehouse (source: Microsoft)
[Click on image for larger view.]
Introducing SQL Data Warehouse (source: Microsoft)
Enterprises can use the new offering in conjunction with other Microsoft data tools such as PowerBI (data visualization), Azure Machine Learning (advanced analytics), Azure HDInsight (managed Apache Hadoop Big Data service) and Azure Data Factory (data orchestration).
"Azure SQL Data Warehouse is based on the massively parallel processing architecture currently available in both SQL Server and the Analytics Platform System appliance," said exec T.K. "Ranga" Rengarajan in a blog post yesterday.
In addition to the new data warehouse, Microsoft introduced several other data-related products yesterday, including Azure SQL Database elastic databases and the Azure Data Lake. The former will "allow you to build SaaS applications to manage large numbers of databases that have unpredictable resource demands, Rengarajan said, while the latter was "built to solve for restrictions found in traditional analytics infrastructure and realize the idea of a 'data lake' -- a single place to store every type of data in its native format with no fixed limits on account size or file size, high throughput to increase analytic performance and native integration with the Hadoop ecosystem." More details can be found here.
About the Author
David Ramel is an editor and writer at Converge 360.