News
AWS Speeds Up Amazon Aurora Relational Database
Amazon Web Services Inc. (AWS) boosted the query time performance of its Aurora relational database service, purpose-built to leverage the benefits of cloud computing.
Amazon Aurora is compatible with MySQL and PostgreSQL databases and is said to include the performance/availability of high-end commercial databases along with the simplicity and cost-effectiveness of open source offerings, while being faster than both.
The fully managed RDBMS service, designed for the cloud, is now said to be even faster with new functionality leveraging cloud attributes like scalability and distributed processing.
With the new addition of Amazon Aurora Parallel Query, AWS said analytical queries of transactional data can be faster by up to two orders of magnitude.
According to AWS, those faster analytical queries occur without the need to copy transactional data into a separate system, benefitting from a new take on parallelized queries. Aurora data is distributed across hundreds of storage nodes in multiple locations in the product's storage layer, and Amazon Parallel Query puts the processing power of all those nodes to work to speed up queries.
"While some databases can parallelize query processing across CPUs in one or a handful of servers, Parallel Query takes advantage of Aurora’s unique architecture to push down and parallelize query processing across thousands of CPUs in the Aurora storage layer," AWS said. "By offloading analytical query processing to the Aurora storage layer, Parallel Query reduces network, CPU, and buffer pool contention with the transactional workload."
AWS spokesperson Jeff Barr explained more in a blog post, in which he provided a graphic to visualize the Aurora storage nodes, with data stored in fast SSDs, across multiple shared storage volumes.
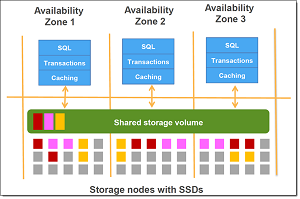 [Click on image for larger view.]
Amazon Aurora (source: AWS)
[Click on image for larger view.]
Amazon Aurora (source: AWS)
"Each node in the storage layer pictured above also includes plenty of processing power," Barr said. "Aurora is now able to make great use of that processing power by taking your analytical queries (generally those that process all or a large part of a good-sized table) and running them in parallel across hundreds or thousands of storage nodes, with speed benefits approaching two orders of magnitude. Because this new model reduces network, CPU, and buffer pool contention, you can run a mix of analytical and transactional queries simultaneously on the same table while maintaining high throughput for both types of queries."
Barr details how to work with the new feature in his post, noting that while it comes at no extra charge, IO costs might increase because of its direct access to storage.
About the Author
David Ramel is an editor and writer at Converge 360.