News
Spark Support, Enterprise SQL Server Added to Amazon Cloud
The Amazon cloud is all about data lately, having just added support for the white-hot Apache Spark project for Big Data analytics and a SQL Server Enterprise Edition machine image offering.
Amazon Web Services Inc. (AWS) exec Jon Fritz announced the Amazon EMR Web service now supports the open source Spark distributed processing framework in a blog post yesterday. Fritz noted that Spark improves upon the batch-oriented MapReduce, an original component of the Apache Hadoop ecosystem, which is ironic in that EMR stands for Amazon Elastic MapReduce.
The MapReduce model has seen several limitations exposed as Big Data analytics has evolved with more demanding use cases and new applications, and Spark uses new technology and approaches to address those limitations.
"We have seen great customer successes using Hadoop MapReduce for large-scale data processing, batch reporting, ad hoc analysis on unstructured data and machine learning (ML)," Fritz said. "Apache Spark, a newer distributed processing framework in the Hadoop ecosystem, is also proving to be an enticing engine by increasing job performance and development velocity for certain workloads."
 [Click on image for larger view.]
The Spark Ecosystem (source: Databricks Inc.)
[Click on image for larger view.]
The Spark Ecosystem (source: Databricks Inc.)
Some of those workloads include stream processing, machine learning and fast, interactive SQL queries. Spark is especially well-suited for such use cases because of features such as in-memory computation and a directed acyclic graph (DAG) execution engine that increases analytic performance, especially in real-time, iterative scenarios.
It also includes multiple libraries for specific applications, such as ML, stream processing and graph processing, among others. These advantages over MapReduce, along with many other features, have reportedly made the Spark the most active open source project under development. Commercial steward Databricks Inc. listed some 230 contributors who helped develop the recently launched version 1.4.
More and more companies are jumping on the Spark bandwagon, and the biggest jump was just taken by IBM, which announced a massive investment in the young technology. Big Blue is incorporating Spark into many of its key data-driven products and services and is channeling immense resources into the project, including devoting more than 3,500 engineers to help out with development efforts. Now IBM is making room for Amazon on that bandwagon.
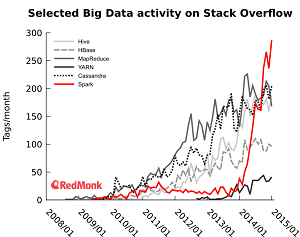 [Click on image for larger view.]
Stack Overflow Activity (source: Redmonk)
[Click on image for larger view.]
Stack Overflow Activity (source: Redmonk)
"Spark on Hadoop YARN is natively supported in Amazon EMR, and you can quickly and easily create managed Spark clusters from the AWS Management Console, AWS CLI, or the Amazon EMR API," the AWS page for Spark states. "Additionally, you can leverage additional Amazon EMR features, including fast Amazon S3 connectivity using the Amazon EMR File System (EMRFS), integration with the Amazon EC2 Spot market, and resize commands to easily add or remove instances from your cluster." There's no additional cost to use Spark in Amazon EMR.
Further exemplifying its data-driven focus, on the same day as the Spark announcement, AWS also unveiled a new Microsoft SQL Server Enterprise Edition Amazon Machine Image (AMI) for the Amazon Elastic Compute Cloud (EC2) in a blog post authored by exec Jeff Barr.
It improves upon the Standard Edition by adding more computing power and memory. Standard allows for using up to 16 cores and 128 GiB of memory, while Enterprise can go up to 32 cores and 244 GiB of memory available in an extra-large instance. The Enterprise Edition comes with SQL Server Enterprise Edition 2012 and SQL Server Enterprise Edition 2014, available in several regions, as explained in the AWS Marketplace.
Barr highlighted the following new and unique features of the offering:
- High availability lets users configure a primary database and up to four active, readable secondary databases into an Always-On availability group.
- Self-service business intelligence through Power View, used to interactively explore and visualize data.
- Data quality services let organizational and third-party reference data be used to profile, cleanse and match your own data.
- Online change functionality lets users restore files and file groups, alter schemas and make indexing changes while a database remains online.
"You can run the AMI on-demand or you can purchase an EC2 Reserved Instance with a one- or three-year term," Barr said.
About the Author
David Ramel is an editor and writer at Converge 360.