Sponsored Content Brought To You By:
How Do You Control a Cloud?
The enterprise cloud ecosystem is complex – use these top 5 best practices to holistically optimize your cloud operations, security and compliance.
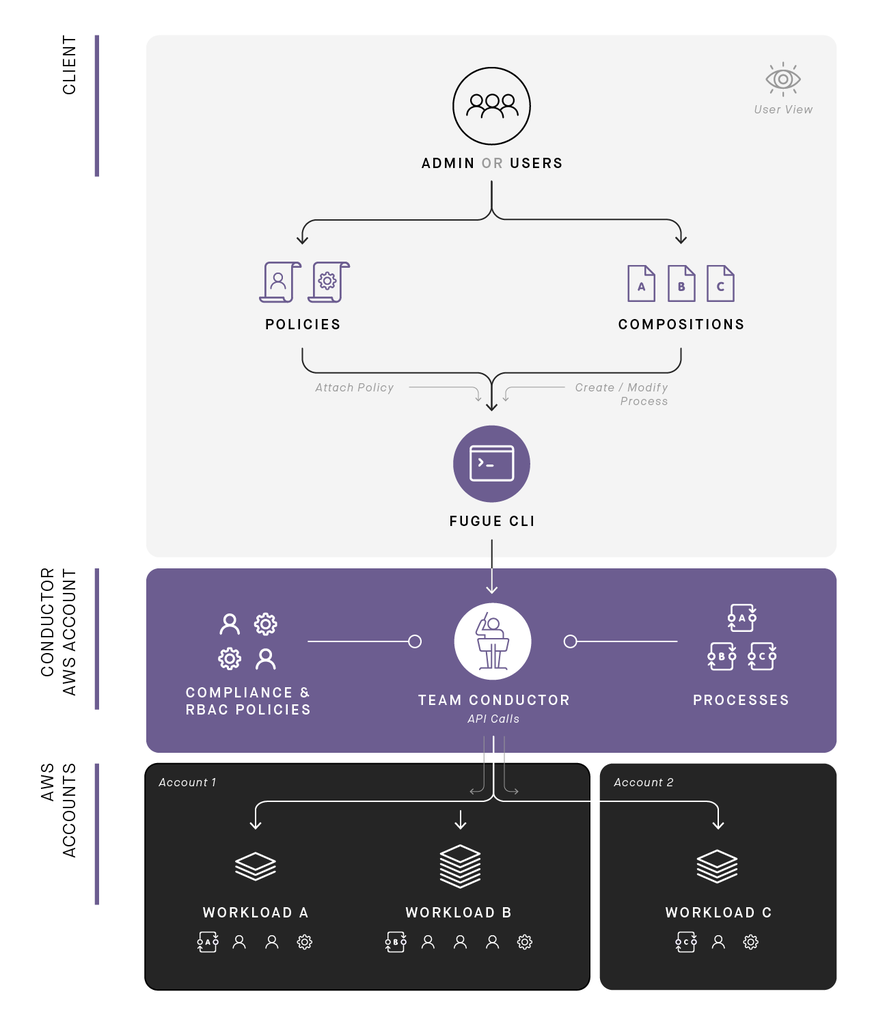 With Fugue, you define infrastructure in compositions, tailor policies suitable to your environments, and issue commands on Fugue's CLI. The Conductor takes it from there—building, operating, enforcing, and tearing down infrastructure via processes. It provides a concise, accurate view of your application's cloud footprint.
With Fugue, you define infrastructure in compositions, tailor policies suitable to your environments, and issue commands on Fugue's CLI. The Conductor takes it from there—building, operating, enforcing, and tearing down infrastructure via processes. It provides a concise, accurate view of your application's cloud footprint.
Transitioning large applications to the cloud is daunting. Architecting from scratch in the cloud
is equally daunting. That's the truth behind the buzz with cloud and it results from at least two
prevailing circumstances. First, it's common to unconsciously architect cloud systems with data
center conventions in mind. But, it's cloud resource and integration principles that should
govern design. Second, the cloud ecosystem is complex -- with tool, service, and component
proliferation that changes frequently and sometimes unpredictably. With cloud, all the pieces
are there to help us, but figuring out how to stack, manage, and tune those pieces to automate
resilience, manage operations securely, and optimize costs isn't easy.
Cloud best practices that account for these challenges are built into Fugue (https://fugue.co).
Five of those practices are examined here, each illustrating Fugue's holistic approach to scaled
cloud operations. The next five years likely will see the rise and democratization of centralized
control systems for cloud ops. Successful systems will solve for complexity and unpredictability at their core layers of architecture and functionality. The practice of bolting on ad hoc features
to meet challenges, instead of blueprinting for them, will face extinction.
Establish Responsible Freedom in the Control Plane
DevOps teams, web developers, and other engineers writing code in an organization need a
degree of freedom to think creatively and put the best application possible into production.
They may use a variety of provisioning and management tools as they work with AWS
resources. They may solve problems utilizing different, "home-grown" options. At the same
time, cloud architects, compliance and audit professionals, and CISOs are dealing with an
equally important set of concerns. It's counterproductive for these professionals, who are
responsible for resilient design, security measures, recovery protocols, compliance policies, and
production standards, to micromanage every aspect of engineering work. But, they do need
control across the entire system to ensure that actions which risk application disruption, expose
vulnerabilities, and result in failed audits never happen.
A CISO, for example, might need to guarantee that all VPCs tie back to the management VPCs
and that nobody has SSH open to the world. In a holistic solution, that means having a central,
secure cloud control plane where important directives are automatically integrated into
operations without burdening individual engineers. Fugue executes this for scaled operations
and offers much more visibility and flexibility than a SaaS or a typical PaaS. It gives the frontline
engineers provisioning and management in a single, declarative interface so they can focus on
improving the app and thinking outside of the box, without violating operational boundaries.
The CISO gets automated configuration assurances and compliance in the control plane to
intrinsically satisfy architecting and security needs.
Identify and Enforce Infrastructure State Automatically
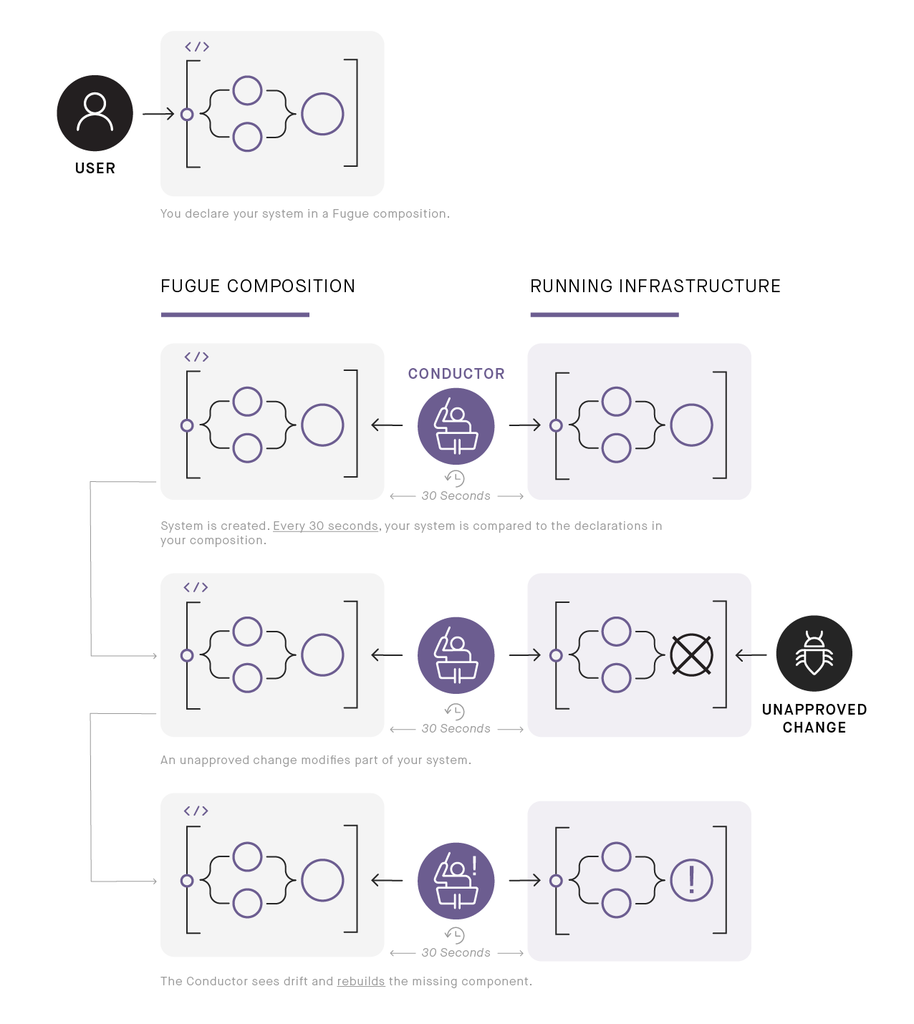 In this series, Fugue's Conductor checks running infrastructure on a schedule against composition declarations, notices an unapproved change not defined in the composition, and responds by rebuilding the manipulated components.
In this series, Fugue's Conductor checks running infrastructure on a schedule against composition declarations, notices an unapproved change not defined in the composition, and responds by rebuilding the manipulated components.
Knowing the actual state of all infrastructure for running applications, with certainty and in real
time, is a big deal. It can eliminate whole sets of problems for SME and larger enterprise
deployments. Having this known view of a system's cloud footprint in one place is even more
useful. And, having infrastructure state automatically checked and enforced if any resources
stray from that view is a defining best practice for bringing control to the cloud.
These practices are built into Fugue's core functionality. The Fugue Conductor, running securely
on an instance inside a designated AWS account, with async messaging patterns and no open
ports, checks and enforces all infrastructure as part of its routine operation. How? The
Conductor continually inspects the state of AWS and writes a representation of that state to a
state cache. It compares what's in the state cache with what's in a Fugue composition -- the
governing, declarative file for a cloud deployment -- and generates a diff. The Conductor then
executes the diff against AWS and updates the state cache. In this manner, unintended or
malevolent changes are caught. A scheduler keeps this cycle continuously initiated on a 30
second loop. The Conductor keeps what's actually running in AWS aligned with what's been
declared in a Fugue composition. So, the composition serves as a consistent, reliable source of
truth because the Conductor automatically honors it. Any configuration drift in running
infrastructure self-heals. Any unauthorized manual intervention self-heals. Any alteration of
policy parameters outside of Fugue's established, secure pattern self-heals.
Simplify Internal and External Policy Compliance
Thinking in terms of infrastructure-as-code is popular, but how do organizations take advantage
of that to bring sanity to large cloud deployments? Put another way, why is coding
infrastructure a best practice for controlling cloud? Version control, streamlined testing, and use
of repeatable patterns are among the answers. But, another important answer resides in
validations. With validations, you can enforce whatever kinds of user-specified business logic or
rules your application requires. For example, you may have a HIPAA rule, needed to meet
external legal requirements, that states certain EC2 instances must not run on shared tenancy
hardware. Or, you may have a rule internal to your organization that says every VPC needs to
allow SSH into it from a management host or that the network block for your VPC must be of a
particular size. As code expressions in the context of a centralized cloud control system,
validations can easily implement external compliance policies and internal ops rules across very
large applications. They can be easily replicated across environments.
Fugue ships with some common validations, but also enables organizations to write their own.
They are just user-definable functions that inspect a type in Fugue composition code and throw
errors if parameters aren't met. They can be imported as a library into a composition with a
single statement or loaded directly onto the Conductor for additional security. A built-in
compiler provides the error and useful message if a validation is violated. No infrastructure is
created until a correction is made and the rules are honored. Client-side validations in Fugue
are, in fact, a way of extending error-checking that the compiler already does. With Conductor-side
validations, no one can skirt policy by not running the validation locally (forgetting an
import statement, etc.) because the Conductor will refuse to run anything that violates policy
attached directly to it. The big picture here is that validations make policy-as-code a reality,
simplifying compliance and keeping it tied to one source of infrastructure truth that is enforced
continuously. Using validations means speed and innovation are not sacrificed for compliance
regimes.
Make Team Collaboration Secure
Validation-supported policy impacts what compositions and their subsequent processes can do
-- that is, how cloud services can spin up. Secure collaboration embedded in policy, on the
other hand, impacts what users can do. So, not only is coding infrastructure a best practice in
cloud control, but coding collaboration is a best practice as well.
Using well organized multi-account management together with coded role-based access
control makes distributing and enforcing permissions an easy, centralized action. It empowers
leadership to map capabilities to the right people in their organization. Team members dealing
with the same or different cloud workloads, environments, and technical priorities can act
without stepping on each other's toes. It improves system security by managing human
intervention in ways that are difficult to bypass on accident or with intention.
Fugue's Multi-Account feature allows you to use a single Team Conductor to manage dozens of AWS accounts, regardless of how resources are instantiated across those
accounts. The Role-based Access Control (RBAC) feature allows you to assign roles with varied
permissions to the account users by writing straightforward policy in the same declarative
language you use for compositions and attaching that policy to your Conductor. These two
features are often inextricably linked in practical use. Effective collaboration at scale in the
cloud requires account and user controls in place that keep teams performing their
responsibilities without risk.
Keep It Simple, Flexible, and Extensible
As complexity grows, chaos tends to grow. In nature, that may well be a sight to behold and a
saving grace, but in cloud computing, it's confusing and expensive. Centralized cloud ops
should be characterized by simplicity and elegance across its interfaces, meaning you've got:
straightforward declarative code that retains the power of functions when needed;
programmatic abstractions in that code as opposed to directory sprawl; compiler error messaging
that leaves no guesswork and a help-centric CLI that makes rollback automation a
trivial job; and, behind-the-scenes component interactions that respect principles of
statelessness, idempotency, eventual consistency, asynchronicity, high availability, and graceful
failure. All of these principles -- aimed at the kind of simplicity that provides clarity -- have to be
architected into a system from the start. Adding tooling on top of a system might provide a
short-term fix, but it creates long-term drag.
Because cloud services are constantly changing and new ones are introduced regularly, having
a flexible, extensible place in the blueprint of an ops system to handle the new APIs is key.
Likewise, an adaptive system that is amenable to any automation workflow and CI/CD
toolchain (whether they involve containers, cluster managers, point solutions for provisioning,
config management, monitoring, etc.) provides another layer of technical flexibility.
Think About Networks and Easy Replication
Let's briefly drill into an area that illustrates the governing problems in cloud that we opened
with -- our anachronistic, often unconscious, clinging to data center conventions and our
grappling with cloud ecosystem complexity. This area has a massive blast radius if done wrong,
if best practices fall by the wayside.
Networking
If a team is new to AWS, transitioning or starting from scratch, networking can be a challenge.
VPC is a critical, ubiquitous AWS networking service. If you make mistakes with configuration
for a single, really important virtual machine, you've still only messed up that virtual machine. If
you mess up networking, you can bring an entire application down. VPC is an area where
Amazon both created new conventions and expanded the use of commonly understood terms,
perhaps understandably because cloud services aren't bound to the data center world.
Nevertheless, those facts create confusion for those who are thinking about laying out subnets
the way you do in an on-premise data center or managing security. In a data center, you're
under constraints regarding subnets that don't exist in AWS and that can result in VPC subnets
being configured in a suboptimal way. Similarly, there's a number of constructs in VPC, like
Security Groups, that sort of map to a real world analogue, but not exactly. This leaves people
to make wrong assumptions around them.
In Fugue, best AWS networking practices are baked into network modules and into concise,
highly readable code that can serve as a template and start off the Fugue composition for your
application. Find the `FugueInk.lw` file at the Scalable Cloud Ops with Fugue source code
page (https://pragprog.com/titles/fugue/source_code) on The Pragmatic Bookshelf publisher's
website for the title (https://pragprog.com/book/fugue/scalable-cloud-ops-with-fugue). In a
few, short blocks of code, you see how complex networking in the cloud (with route tables,
Internet Gateways, subnets, and other resources) can be abstracted into concise, readable,
reliable, programmatic abstractions. For further examples, take a look at the Fugue networking
docs (https://docs.fugue.co/fugue-by-example-build-network.html). The usefulness of this
approach becomes apparent when executing networks manually or with other approaches.
It's also worth noting that, if you're one engineer managing your scope of work, you can
basically keep it all in your head. But, if you're working with a team, being able to have your
infrastructure-as-code in a centralized code repository that people can look at, that you can use
for code reviews, that you can run through a CM process becomes inescapably important when
you're working with services like networking. Networking tends to be a shared resource. Even if
everyone's managing virtual machines in their own ways, having a central place of truth and
trust for the shared resource is critical.
Use a System That Knows the Future Is Unpredictable
Many prescient technologists talk about what's coming or probably coming in a year, five years,
ten, and that wisdom is invaluable. But the devil is frequently in the details. And the only
certainty is that we can't predict those details. So, to control a cloud from stem to stern means
building or using a system that's highly adaptive: almost any circumstance can be accounted
for when infrastructure and collaboration are code and when the machine, not humans, is
responsible for constantly aligning actual state with a declared definition of your cloud.
This article is part of a marketing program that allows advertisers to share their content with our audience. The editors of this site were not involved with the creation of this content.